Shogun’s third Google Summer of Code just ended with our participation in the mentor summit at Google’s headquarter in Mountain View and the release of Shogun 3.0 (link) What a great summer! But let’s start at the beginning…

Shogun is a toolbox that offers a unified framework for data-analysis, or in buzz words: machine learning, for a broad range of data types and analysis problems. Those not only include standard tools such as regression, classification, clustering, etc, but also cutting edge techniques from recent developments in research. One of Shogun’s most unique features is its interfaces to a wide range of mainstream computing languages.
In our third GSoC, we continued most of the directions taken in previous years such as asking students to contribute code in the application process for them to be considered. For that, we created a list of smaller introductory tasks for each of the GSoC projects that would become useful later in the project. While allowing students to get used to our development process, and increasing the quality of the applications, this also pushed the projects forward a bit before GSoC even started. The number of applications did not suffer through that (57 proposals from 52 students) but even increased compared to the previous year (48 proposals from 38 students) — this seems to be a trend.
This summer, we also had former GSoC students mentoring for the first time: Sergey Lisitsyn and me (mentoring two projects). Both of us joined in 2011. In addition, the former student Fernando Iglesias participated again and former student Viktor Gal stayed around to work on Shogun during GSoC (and did some massive infrastructure improvements). These are very nice long term effects of continuous GSoC participation. Thanks to GSoC, Shogun is growing constantly both in terms of code and developers.
As in 2012, we eventually could give away 8 slots to some very talented students. All of them did an awesome job on some highly involved projects covering a large number of topics. Two projects were extensions of previous ones:
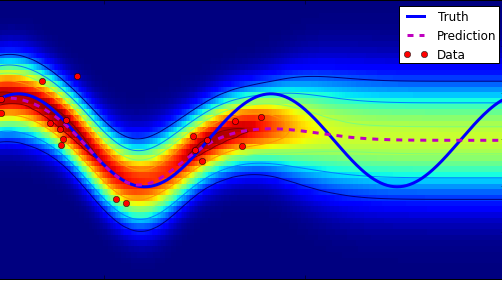
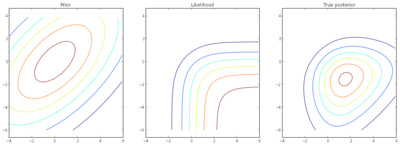
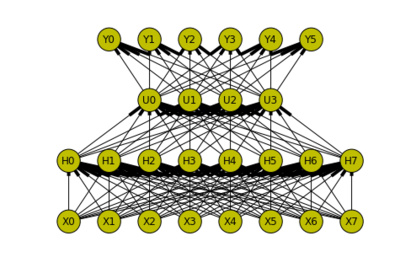
Roman Votjakov extended last year’s project on the popular Gaussian Processes for handling classification problems and Shell Hu implemented a collection of algorithms within last year’s structured output framework (for example for OCR)


Fernando Iglesias implemented a new algorithm called metric learning, which plays well together with existing methods in Shogun.
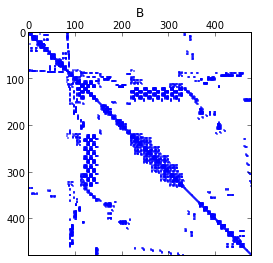
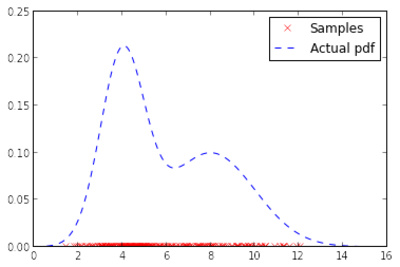
Another new algorithm came from Soumyajit De, who has implemented an estimation method for log-determinants of large sparse matrices (needed for example for large-scale Gaussian distributions), and implemented a framework for linear operators and solvers, and fundamentals of an upcoming framework for distributed computing (which is used by his algorithm) on the fly.
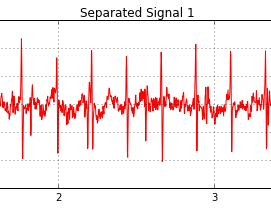
Evangelos Anagnostopoulos worked on feature hashing and random kitchen sinks, two very cool tricks to speed up linear and kernel-based learning methods in Shogun. Kevin Hughes implemented methods for independent component analysis, which can be used to separate mixtures of signals (for example audio, heart-beats, or images) and are well known in the community.

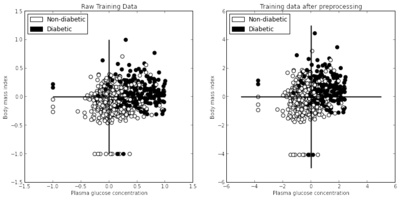
Last but not least, Liu Zhengyang created a pretty web-framework for running Shogun demos from the web browser and did add support for directly loading data from the mldata website. Evgeniy Andreev improved Shogun’s usability via integrating native support for various popular file formats such as CSV and protobuf.
You might have noticed the links in the above text (and images). Most of them are the final reports of the students in the form of IPython notebooks, an awesome new open-source tool that we started using for documentation. We are very proud of these. See http://shogun-toolbox.org/page/documentation/notebook/ for a list of all notebooks. Also check out the web-demo framework at http://www.shogun-toolbox.org/page/documentation/demo/ if you haven’t yet.
IPython also features Shogun in the cloud: Former student Viktor Gal did setup http://cloud.shogun-toolbox.org which is an IPython notebook server ran by us. It allows you to play with Shogun-python from any web-browser without having to install it. You can try the existing notebooks or write your own. Give it a shot and let us know what you think!
This year’s GSoC also was the most productive one for us ever. We got more than 2000 commits changing almost 400000 lines in more than 7000 files since our last release before GSoC.
Students! You all did a great job and we are more than amazed what you all have achieved. Thank you very much and we hope some of you will stick around.
Besides all the above individual projects, we encouraged students to work together a bit more to enable synergistic effects. One way we tried to implement this was through a peer review where we paired students to check each others interface documentation and final notebooks. We held the usual meetings with both mentors and students every few weeks to monitor progress and happiness, as well as asking students to write weekly reports. Keeping our IRC channel active every day also helped a lot in keeping things going.
My personal experience with mentoring was very positive. It is very nice to give back to the community. I tried to give them the same useful guidance that I received back then, and probably learned as much as my students did on the way. Having participated in GSoC 2011 and 2012, the change of perspective as a mentor was interesting, in particular regarding the selection process. Time wise, I think Google’s official statement of 5 hours per student per week is underestimating things quite a bit (if you want to get things done), and of course there is no upper bound on time you can spend.
Our plan of pairing external mentors with internal developers worked smoothly. As most of our mentors are scientists who tend to be very busy, it is sometimes hard for them to review all code on their own. Combining big-picture guidance with the in-depth framework knowledge of the paired core developers allowed for more flexibility when allocating mentors for projects. Keep in mind that Shogun is still being organised by only five people (4 former students) plus a hand full of occasional developers, which makes it challenging to supervise 8 projects.
Another change this year was that writing unit-tests were mandatory to get code merged, which made the number of unit tests grew from 50 to more than 600. In the past years, we had seen how difficult it is to write tests at the end of projects, or maintain untested code. Making students do this on-the-fly drastically increased the stability of their code. A challenging side-effect of this was that many bugs within Shogun were discovered (and eventually fixed) which kept students and developers busy.

As for Shogun itself, GSoC also boosts our community of users, which became so active this year that decided to organise a the first Shogun workshop in Berlin this summer. We had something over 30 participants from all over the world. The Shogun core team also met for the first time in real life, which was nice! We had a collection of talks, discussions, and hands-on sessions. Click here and here for videos and slides.
 October brought the mentor summit, which I attended for the first time. This was such a cool event! There was a hotel with hot-tub, lots of goodies on the google campus as for example an on-site barista (!), a GSoC mentor with a robot-dog, and loads of loads of interesting people from interesting open-source projects. Some of these were new to me, some of them are projects that I have been checking out for more than 10 years now.I attended a few fruitful sessions, for example on open-source software for science. Sören hang out with the people he knew from previous years and the cool Debian guys (for which he is a developer too).
October brought the mentor summit, which I attended for the first time. This was such a cool event! There was a hotel with hot-tub, lots of goodies on the google campus as for example an on-site barista (!), a GSoC mentor with a robot-dog, and loads of loads of interesting people from interesting open-source projects. Some of these were new to me, some of them are projects that I have been checking out for more than 10 years now.I attended a few fruitful sessions, for example on open-source software for science. Sören hang out with the people he knew from previous years and the cool Debian guys (for which he is a developer too).
After the summit, the Shogun mentor team went hiking in the south Californian desert – I even climbed a rock.
What a great summer!



















 says it all: \"nasty chimney\"")






















")




.")