No, this is not about Fernando’s and mine honeymoon …
The Shogun team just released version 4.0 of their community driven Machine Learning toolbox. This release most of all features the work of our 8 Google Summer of Code 2014 students, so this blog post is dedicated to them — you guys rock. This also brings an end to yet another very active year of Shogun: we organised a second workshop in Berlin, and I presented Shogun in to the public in London, New York and Berlin.

For the 4th time, Shogun participated in Google’s wonderful program which more than anything boosted the team’s size and motivation. What else makes people spend sleepless nights hunting bugs for the sake of Machine Learning for everyone? This year was the first time that I organised our participation. This ranged from writing the application last second, harrassing potential mentors until they say ‘yes’, to making up overly ambitious projects to scare students away, and ending up mentoring too many students on my own. Jokes aside, this was a very challenging (in particular time-wise) but also a very rewarding experience that definitely sharpened my project organisation skills. As in the previous year, I tried to fuse my scientific life and Shogun’s GSoC participation — kernel methods and variational learning is something I touch on a daily basis at Gatsby. Many mentors were approached after having met them at scientific Machine Learning conferences, and being exposed to ML on for some years now, it is also easier to help students implement and write about popular ML algorithms.
Here is a list. (Note that all projects come with really nice IPython notebooks — something that we continued to insist on from last year.)
Fundamental ML algorithms by Parijat Mazumdar (parijat). Mentor: Fernando
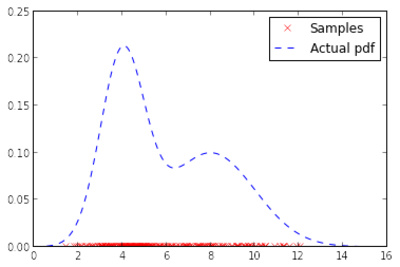
Shogun needs more standard ML algorithms. Parijat implemented some of those: random forests, kernel density estimation and more. Parijat’s code quality is amazing and together with Fernando’s superb mentoring skills (his first time mentoring), this project is likely to have been very sustainable.
Notebook random forest, notebook KDE.
Kernel testing and feature selection by Rahul De (lambday). Mentor: Dino Sejdinovic, Heiko
Previous year’s student lambday continued to rock. First, he massively extended my 2012 project on kernel hypothesis testing to Big Data land. Dino, who was one of the invited speakers in the Shogun workshop last summer, and I are actually working on a journal article where we will use this code. Second, he extended the framework to perform feature selection via dependence measures. Third, he initiated and guided development of a framework for unifying Shogun’s linear algebra operations. This for example can be used to change existing algorithms from CPU to GPU with a compile switch — useful also for our deep learning project.
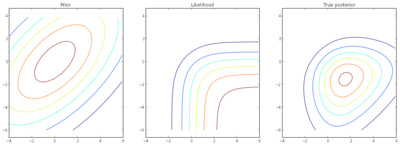
Variational Inference for Gaussian Processes by Wu Lin (yorkerlin). Mentor:Heiko, Emtiyaz Khan
In our third GSoC project on GPs, Wu took a couple of state-of-the-art approximate variational inference methods developed by Emiyaz, and put them into Shogun’s framework. The result of this very involved and technical project is that we now have large-scale classification using GPs. Emtiyaz also was a speaker at ourworkshop.
Notebook
Shogun missionary by Saurabh. Mentor:Heiko
The idea of this project was to showcase Shogun’s abilities — sometimes we definitely need to work on. Saurabh wrote a couple of Notebooks that are essentially ML tutorials using Shogun. If you want to know about ML basics, regression, classification, model-selection, SVMs, multiclass, multiple kernel learning this was for you. He also extended our web-demo framework to for example include model-selection for GPs.
OpenCV integration by Kislay. Mentor: Kevin
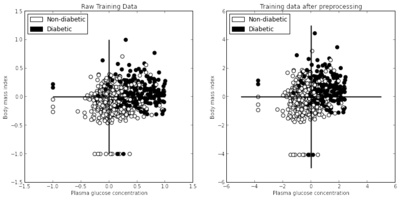
Kislay, after writing a very cool notebook on PCA for his application, wrote data-structures to bridge between Shogun and OpenCV. The project was supervised by Kevin, who is also one of our former GSoC students This makes it possible to use the too libraries together in a neat way.
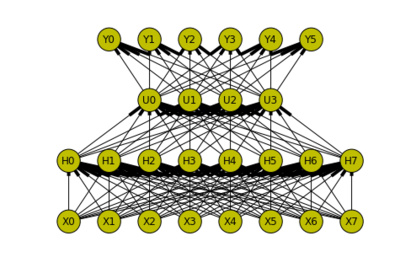
Deep learning by Khaled Nasr. Mentor: Theofanis, Sergey
The hype is on! After NIPS, Facebook, GoogleDeepmind, Shogun now also joined 😉 Khaled did a very good job in coding up the standard ones, and was involved in generalising Shogun’s linear algebra on the fly with lambday. This is a project that is likely to have a second part. Check his superb notebooks on deep belief neural networks, convolutional networks,autoencoders, restricted Boltzman machines

SO Learning with Approximate Inference by Jiaolong. Mentor: hushell, Thoralf
This was another project that was (co-)mentored by a former GSoC student. With the help his mentors, Jialong implemented various approximate inference methods for structured output (SO) models. Check out his notebook.
Large-Scale Multi-Label Classification by Abinash. Mentor: Thoralf
Another project involving our structured output expert Thoralf as mentor. Abinash implemented large-scale multilabel learning — beating scikit learn‘s implementation both in runtime and accuracy. The last experiment is described in this notebook.

Finally, we sent two of our delegates (Thoralf and Fernando) to the 10th year jubilee mentor summit in California in late October. Really cool: I got lucky and won Google’s lottery on some extra places, so I could also join. The summit once again was overly colourful, bursting with creative minds who have the most diverse set of opinions and approaches, but who are all united by their excitement about open-source. The beauty of this community to me really lies in the people who do work purely driven by their interest on *the thing itself*, independent of competitive and in particular commercial interests — sometimes almost to an extend that is beyond any form of compromise. A wonderful illustration of this was when at the mentor summit, during the reception in the Tech museum in San Jose: Google’s speaker and head of finance Patrick Pichette (disclaimer: not sure, don’t quote me on this) who is the boss of Chris DiBona, who himself organises the GSoC, searched to inspire the audience to “think BIG” and to “change the lifes of GSoC students”. Guest speaker Linus Torvalds 10 minutes later then contemplates that he could not be a GSoC mentor as he would scare people away and that the best way to get involved in open-source is to “start small” — a sentence after which P.P. left the room. Funny enough: in GSoC, this community is then hugged by a super capitalistic American internet company — and gladly lets it happen: we all love GSoC and Shogun certainly would not be where it is without it. I also want to mention the day Google rented a whole theme park for us nerds — which made Fernando try a roller-coaster for the first time after being pushed by MLPack maintainer Ryan and myself. After being horrified at first, he even started to talk about C++ the second or third time.

As you would expect from attending such geeky meetings, Thoralf, Fernado, and I also spent quite some time hacking Shogun, discussing ideas until late night (of course getting emotional about them 🙂 ). I managed to take a picture of Fernando falling asleep while hacking Shogun’s modular interfaces. Some of those ideas are collected on our wiki.
- Improve usability
- Making Shoun more modular and slim
- Improving Shogun’s efficiency
Some of those ideas are also part of our theme for our GSoC 2015 application and our planned Hackathon. We have come to a point where we seriously need to focus on application and stability rather than adding more and more cutting-edge algorithms — Shogun’s almost 15 year old framework needs a face lift. GSoC students will see that this years project ideas will focus on cleaning up the toolbox and implement ML applications.
Meet the Shogun/MLPack crew, as nerdy as it gets 😉




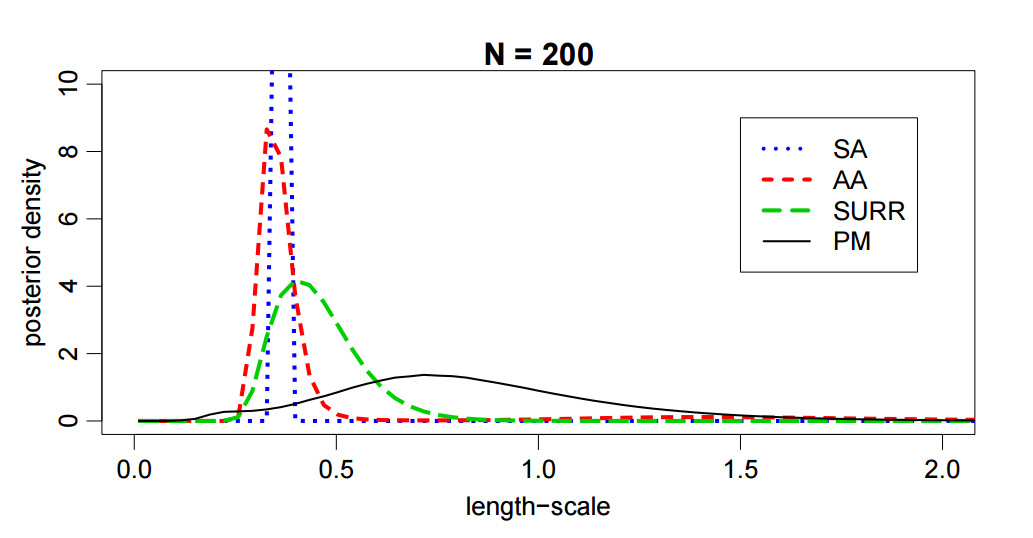



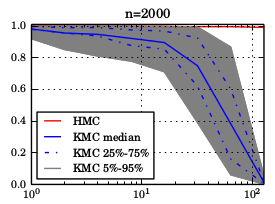


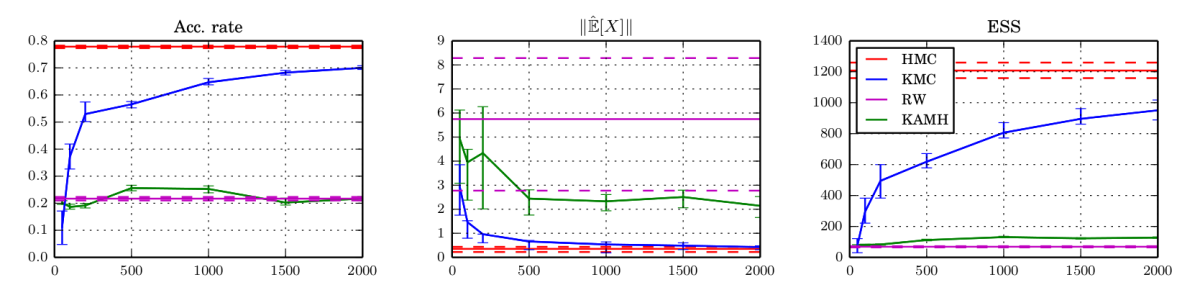
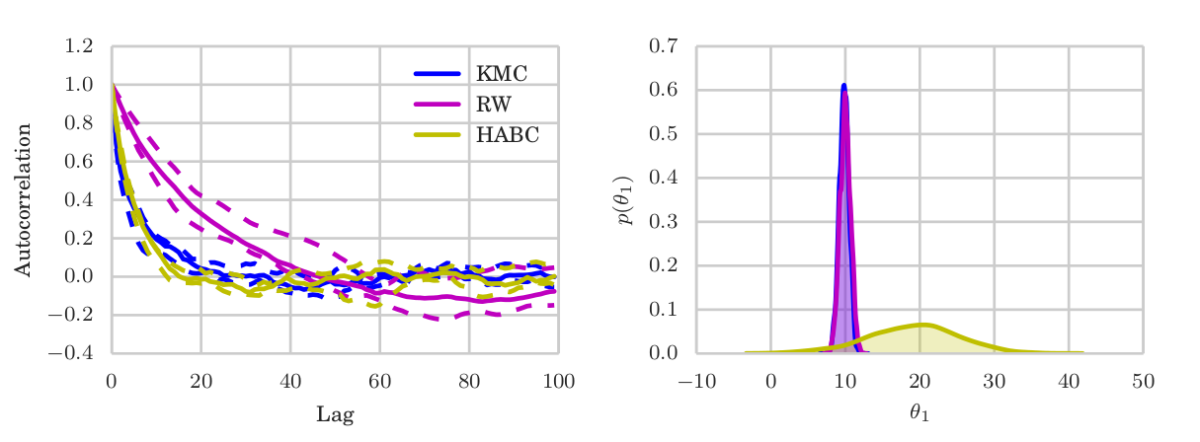

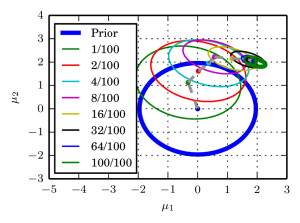

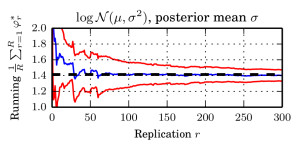


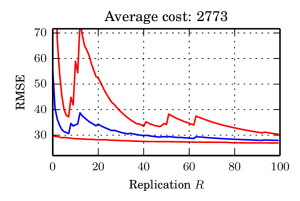




 We argue that there exists a class of posterior distributions for that HMC is not available, while the distribution itself is still highly non-linear. You get them as easy as attempting binary classification with a
We argue that there exists a class of posterior distributions for that HMC is not available, while the distribution itself is still highly non-linear. You get them as easy as attempting binary classification with a