I recently finished working on my Master project here at UCL. It was supervised by Arthur Gretton and Massimiliano Pontil and was about kernel selection for a linear version of the Maximum Mean Discrepancy, a kernel based two-sample test. Download report here.
Given sets of samples of size m from two probability distributions, a two-sample test decides whether the distributions are the same or different with some confidence level. The linear time MMD statistic is defined as
\[\text{MMD}_l^2=\frac{1}{m}\sum_{i=1}^{m}h((x_{2i-1},y_{2i-1}),(x_{2i},y_{2i}))\]
where
\[h((x_{i},y_{i}),((x_{j},y_{j}))=k(x_{i},x_{i})+k(y_{i},y_{i})-k(x_{i},y_{j})-k(x_{j},y_{i})\]
and \(k\) is an RKHS reproducing kernel (I used the Gaussian kernel only).
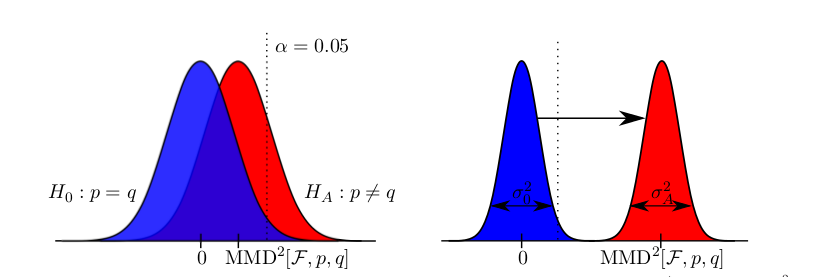
A two sample test works simply as this: if this statistic (computed on sample data) is larger than a computed threshold (also on data), it is likely that the two sets of samples are from different distributions.

(Null and alternative distributions of MMD statistic, red area represents type I error, blue area represents type II error)
The linear time version is highly interesting for large-scale problems since one does not have to store data in order to compute it. Instead, it is possible to compute statistic and threshold in an on-line way.
The work contains three main contributions:
- An on-line version for the already existing linear time two-sample test. More important, it was shown in experiments that in some situations, the linear time test is a better choice than the current quadratic time MMD state-of-the-art method. This for example happens when problems are so hard that the amount of data necessary to solve them does not fit into computer memory. On the blobs dataset described in the work,
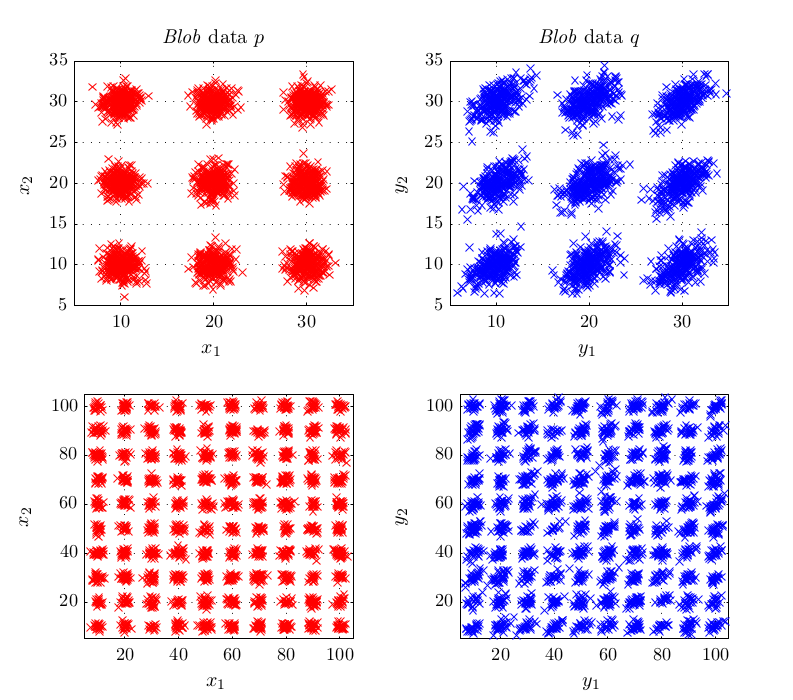 a quadratic time test on the maximum processable amount of data reached a bad type II error while with the linear time version and much more data, almost zero type II error could be reached. Another case is when simply infinite data (but finite computation time) is available: the (adaptive) linear time test reaches lower type II error that its quadratic counterpart.
a quadratic time test on the maximum processable amount of data reached a bad type II error while with the linear time version and much more data, almost zero type II error could be reached. Another case is when simply infinite data (but finite computation time) is available: the (adaptive) linear time test reaches lower type II error that its quadratic counterpart.

- A description of a criterion that can be used for kernel selection for the linear time MMD. Null and alternative distribution of the statistic have appealing properties that can be exploited in order to select the optimal kernel in the sense that a test’s type II error is minimised. The criterion is the ratio of MMD statistic and its standard deviation. This pulls null and alternative distribution apart while minimising their variance.
 In experiments, this criterion performed better or at least equal than existing methods for kernel selection. This is especially true when the length scale at which probability distributions differ is different to the overall length scale, as for example in the above shown blobs dataset.
In experiments, this criterion performed better or at least equal than existing methods for kernel selection. This is especially true when the length scale at which probability distributions differ is different to the overall length scale, as for example in the above shown blobs dataset.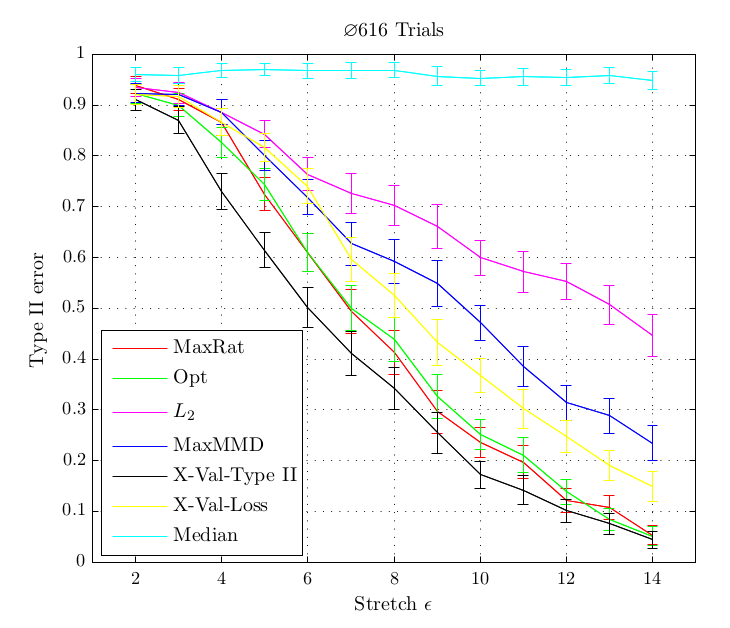
(Opt and MaxRat methods are based on the criterion and perform better than existing methods, X-Val-Type II is another newly described method, blobs dataset) - A MKL-style generalisation of two-sample testing on the base of finite linear combinations of baseline kernels of the form
\[
\mathcal{K}:=\{k : k=\sum_{u=1}^d\beta_uk_u,\sum_{u=1}^d\beta_u\leq D,\beta_u\geq0, \forall u\in\{1,…,d\}\}
\]
Optimal weights of these combinations can be computed via solving the convex program
\[
\min \{ \beta^T\hat{Q}\beta : \beta^T \hat{\eta}=1, \beta\succeq0\}
\]
where \(\hat{Q}\) is a linear time estimate of the covariance of the MMD estimates and \(\hat{\eta}\) is a linear time estimate of the MMD.Whenever combined kernels may capture more information relevant distinguishing probability distributions than one kernel, this method leads to better results.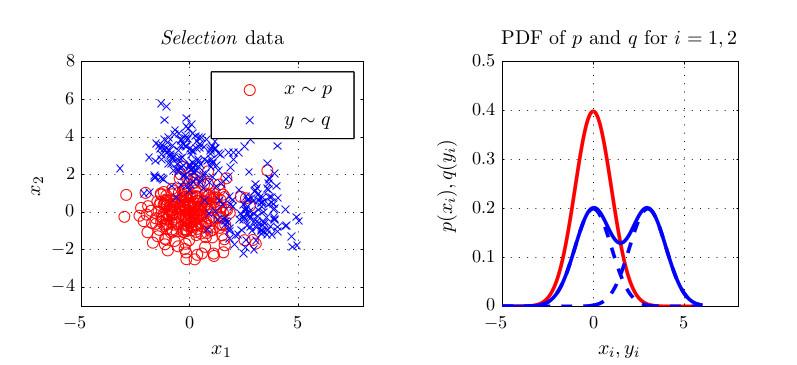
(A dataset where two dimensions provide more information than one)

(Opt and \(L2\) use combined kernels)
It also has an interesting feature selection interpretation in the sense that the two-sample test provides information on which kernels (and therefore domains) are useful for locating distinguishing characteristics of distributions.
All above plots and results can be found in the report. Many results are joint work and went to the article “Optimal kernel choice for large-scale two-sample tests”, which was accepted at NIPS 2012 while my report was written. Many thanks to the other authors, in particular to Arthur Gretton, Dino Sejdinovic, Bharath Sriperumbudur, and Massimiliano Pontil for all the fruitful discussions and guidance.