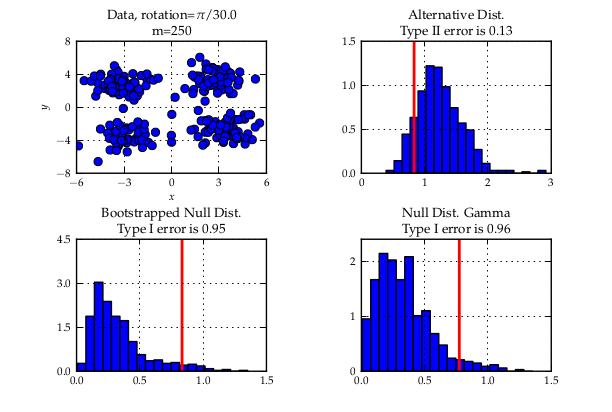
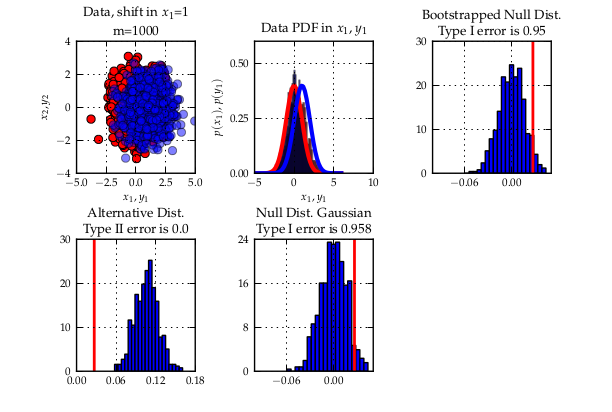
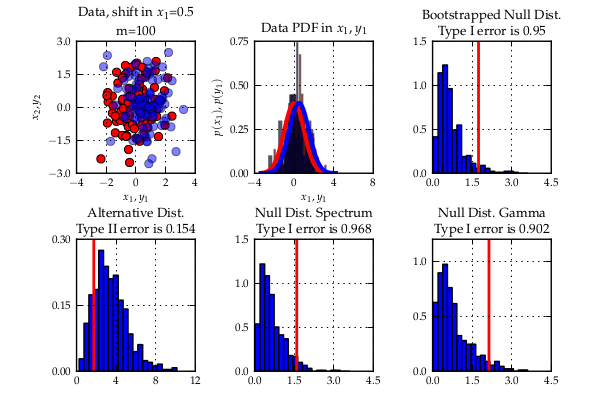
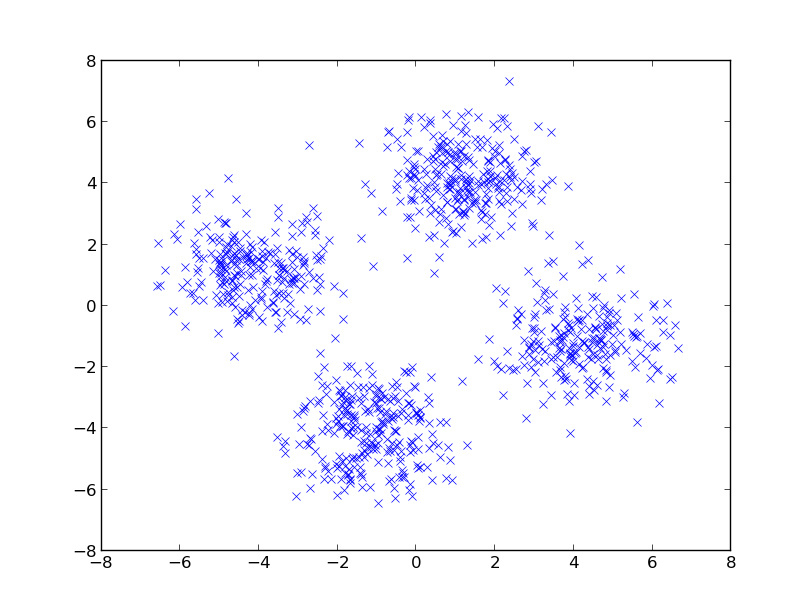
Since a few weeks, GSoC 2012 is over. It has been a pretty cool summer for me. As last year, I learned lots of things. This year though, my project a bit more research oriented — which is nice since it allowed me to connect my work for SHOGUN with the stuff I do in Uni. I even mentioned it in my Master’s dissertation (link) which also was about statistical hypothesis testing with the MMD. Working on the dissertation at the same time as on the GSoC was sometimes exhausting. It eventually worked out fine since both things were closely related. I would only suggest to do other important things if they are connected to the GSoC project. However, if this condition is met, things multiply in terms of the reward you get due to synergistic effects.
The other students working for SHOGUN also did very cool projects. All these are included in the SHOGUN 2.0 release (link). The project now also has a new website so its worth taking a closer look. Some of the other (really talented) guys might stay with SHOGUN as I did last year. This once more gives a major boost to development. Thanks to all those guys. I also owe thanks to Sören and Sergey who organised most things and made this summer so rewarding.
In the near future I will try to put in some extensions to the statistical testing framework that I though of during the summer but did not have time to implement: On-line features for the linear time MMD, a framework for kernel selection which includes all investigated methods from my Master’s dissertation, and finally write unit-tests using SHOGUN’s new framework for that. I will update the SHOGUN project page of my website (link). I might as well send some tweets to SHOGUN’s new twitter account (link).