Finally, I started on kernel based (in)dependence tests last week. These are tests that try to find out whether for two random variables \(\textbf{x},\textbf{y} \) are independent, i.e. whether their joint distribution factorises into the individual ones. The null hypothesis (that may be rejected) is \[ H_0:P_\textbf{x}P_\textbf{y}=P_{\textbf{x}\textbf{y}}\]
These kind of tests basically work like two-sample tests: Given one set of samples from each random variable
\[ Z=(X,Y)=\{(x_1,y_1,…,(x_m,y_m)\}\]
a test statistic is computed and then compared against the distribution of the statistic under the null-hypothesis. If the position is in an upper part of it, the null-hypothesis is rejected since it is unlikely that the current value was generated by it.
The class of independence tests I will implement for my project are all based on the Hilbert Schmidt independence criterion (HSIC), which takes out the above procedure to an reproducing kernel Hilbert space (RKHS). The (biased version of the) HSIC statistic itself is simply given by
\[\text{HSIC}_b(Z)=\frac{1}{m^2}\text{trace}(KHLH)\]
where \(K,L \) are kernel matrices of the input samples \( X,Y\) in some RKHS and \(H=I-\frac{1}{m}\textbf{1}\textbf{1}^T\) is a centring matrix.
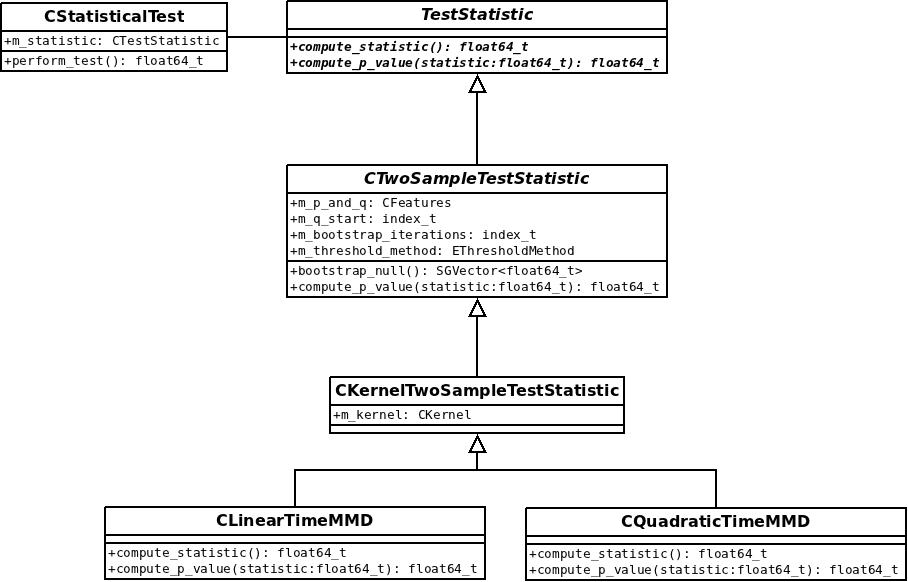
I integrated a general modular framework for independence tests into SHOGUN. The HSIC class is the first kernel-independence test that works. Interfaces are very similar to the two-sample test, however, they are not quite the same for various reasons. That’s why there is another class for independence testing next to the one for two-sample testing.
As for the two-sample tests, the null-distribution may simply be approximated by bootstrapping, i.e. merging the samples and computing the statistic for many times. This is now possible for any independence test. Another method to approximate the null-distribution for HSIC is fitting a Gamma distribution [1] as
\[m\text{HSIC}=\frac{x^{\alpha-1}\exp(-\frac{x}{\beta})}{\beta^\alpha \Gamma(\alpha)} \] where
\[\alpha=\frac{(\textbf{E}(\text{HSIC}_b(Z)))^2}{\text{var}(\text{HSIC}_b(Z))} \quad \text{and}\quad\beta=\frac{m\text{var}(\text{HSIC}_b(Z))}{\textbf{E}(\text{HSIC}_b(Z))}\]
It’s also already implemented! There are already modular interfaces for the new classes and some simple tests. I will extend these during this weak. Time passes fast: The mid-term-evaluation is this week already. I pretty much enjoyed the first half 🙂
[1]: Gretton, A., Fukumizu, K., Teo, C., & Song, L. (2008). A kernel statistical test of independence.