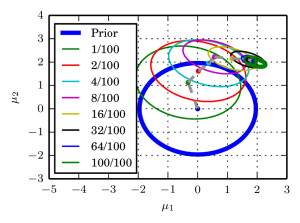

Starting from $p(mu)$, we take steps on a single posterior path by subsequently doubling the data-size, eventually reaching the full posterior, which is proportional to $p(mathbf{mu})prod_{i=1}^{100}p(mathbf{x}_i|mathbf{mu})$. Shown are 2D contour plots of the partial posterior densities.