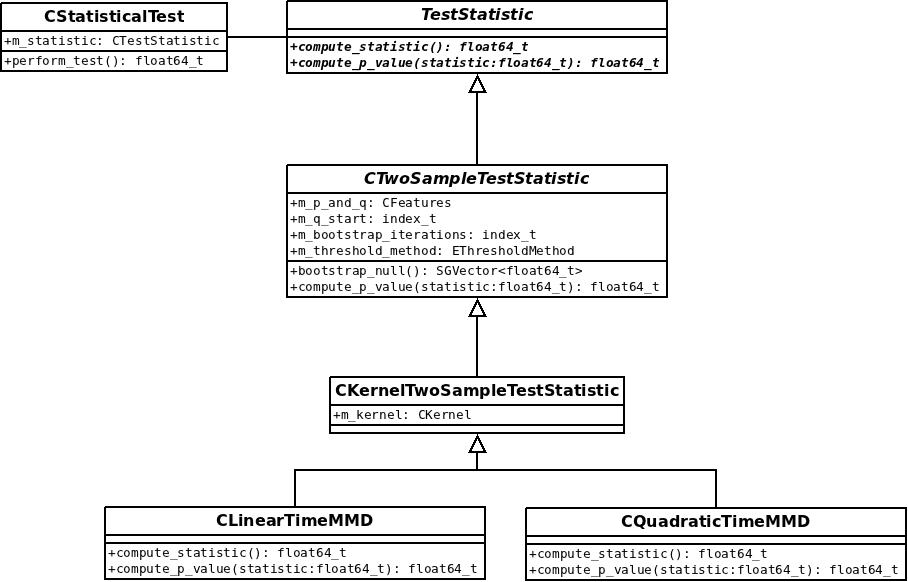
Step by step, my project enters a final state 🙂
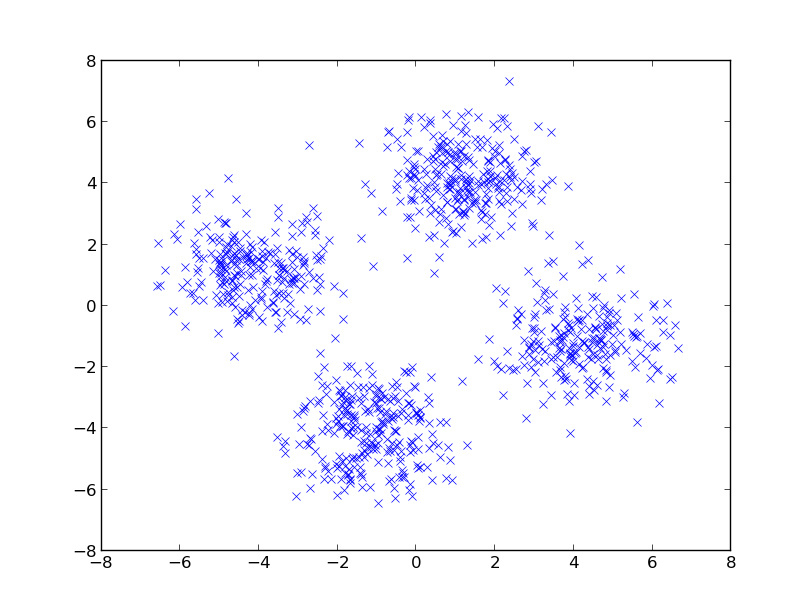
Last week, I added new data generation methods, which are used from a new example for independence tests with HSIC. It demonstrates that the HSIC based test is able to capture dependence which is induced by rotating data that has zero correlation — one of the problems from the paper [1]. Here is a picture; the question is: are the two dimensions dependent? Or moreover, is a test able to capture that? (correlation is almost zero, dependence is induced via rotation)
I also realised that my current class structure had problems doing bootstrapping for HSIC, so I re-factored a bit. Bootstrapping is now also available for HISC using the same code that does it for two-sample-tests. I also removed some redundancy — both independence and two-sample tests are very similar problems and implementations should share code where possible.
Another thing that was missing so far is to compute test thresholds; so far, only p-values could be computed. Since different people have different tastes about this, I added both methods. Checking a test statistic against a threshold is straight-forward and gives a binary answer; computing a p-value gives the position of the test statistic in the null-distribution — this contains more information. To compute thresholds, one needs the inverse CDF function for the null-distribution. In the bootstrapping case, it is easy since simply the sample that corresponds to a certain quantile has to be reported. For cases where a normal- or gamma-distribution was fitted, I imported some more routines from the nice ALGLIB toolbox.
For this week, I plan to continue with finishing touches, documentation, examples/tests, etc. Another idea I had is to make the linear time MMD test work with SHOGUN’s streaming features, since the infinite or streaming data case is the main area for its usage.
[1]: Gretton, A., Fukumizu, K., Teo, C., & Song, L. (2008). A kernel statistical test of independence. Advances in Neural Information Processing Systems